Answers to some of the commonly asked questions on the Reverse ETL feature.
4 minute read
Reverse ETL feature
How do I use the Reverse ETL feature?
RudderStack’s Reverse ETL feature lets you set up your data warehouse as a source in RudderStack and route the data residing in it to your preferred destination.
To use this feature, follow these steps:
Set up a Reverse ETL source in RudderStack.
Connect it to a new or existing destination.
Specify the warehouse data you want to sync to that destination.
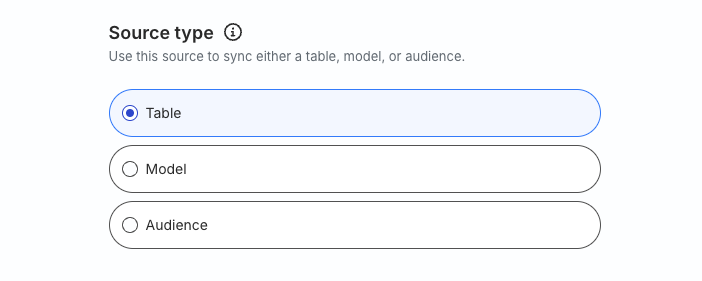
What is the difference between the Table, Model, and Audience options when creating a Reverse ETL source?
When creating a new Reverse ETL source, you are presented with the following three options from which RudderStack syncs the source data:
When you choose Table, RudderStack imports all data associated with the specified warehouse table during the sync.
When you choose Model, RudderStack imports the data by running the query specified in the connected model during the sync.
When you choose Audience, RudderStack syncs the audience you created in the RudderStack dashboard.
Note that:
MySQL and PostgreSQL sources support syncing data only from a warehouse table and model. Hence, you will not see the Audience option while setting up this source.
S3 supports syncing data only from your S3 bucket.
Can I use Reverse ETL to ingest streaming data from the warehouse?
Reverse ETL does not support ingesting streaming data. It is not built to handle the rapidly changing data in the warehouse.
Can I connect a Reverse ETL source to multiple destinations?
Yes — RudderStack supports connecting a Reverse ETL source to multiple destinations.
Event usage/billing in 1:many connections
When sending data from a Reverse ETL source to multiple destinations, RudderStack sends the record to each destination separately — this means you will be charged on a per connection basis.
See Set Up Reverse ETL Connection for more information on connecting your Reverse ETL sources to destinations in RudderStack.
Can I connect multiple Reverse ETL sources to a single destination?
RudderStack supports connecting multiple Reverse ETL sources to a single downstream destination. However, this feature is available only for the below destinations currently — support for more integrations is coming soon.
Can I connect a warehouse source to a warehouse destination in RudderStack?
No - RudderStack does not support connecting a Reverse ETL (warehouse) source to a warehouse destination.
Why can’t I add a Reverse ETL source to an already configured destination?
The Reverse ETL feature supports only source-driven configuration of your pipeline. So, you need to configure a new or existing Reverse ETL source in RudderStack and then connect it to a new or existing destination.
Data syncs
What is the _RUDDERSTACK schema used for?
RudderStack uses the _RUDDERSTACK schema (rudderstack_ for BigQuery) created in your warehouse to store the state of each data sync. Hence, you should not change this name.
You are required to create this schema in your warehouse (for example, Snowflake) before setting up the Reverse ETL source in RudderStack.
How much time does it take for the synced data to appear in the destination?
RudderStack sends the records to the destination pretty quickly. It takes around a couple of minutes in most cases but it may take longer depending on the destination type. However, the sync metrics may take some more time (around 10 minutes) to reflect in the RudderStack dashboard.
If you see a prompt on the sync stating “Records sent to destination, finalizing sync stats”, it indicates that the records have successfully reached the destination.
Event replay
Can I replay data from a Reverse ETL source in case of failure?
RudderStack does not support replaying data from Reverse ETL sources.
Sync modes and schedule settings
What is the difference between Basic, CRON, and Manual schedule settings?
When creating a new Reverse ETL source, RudderStack lets you schedule your data imports and define how and when the data syncs will run.
RudderStack defines the following three sync schedule types:
Schedule type
Description
Basic
Runs syncs at a user-specified time and interval.
CRON
Runs syncs based on a user-defined CRON expression.
Manual
User triggers the data syncs manually.
What is the difference between Upsert and Mirror mode when syncing data?
RudderStack supports two sync modes (available based on the source and the chosen destination) that let you define how you want to sync your data. These are Upsert and Mirror mode.
In the Upsert mode, RudderStack supports insertion of new records and updates to the existing records, while syncing data to the destination.
In the Mirror mode, RudderStack ‘mirrors’ the source by keeping the destination data the same as the source data. It performs insertion, updates, and deletion of records while syncing data to the destination.
What is the difference between the Full and Incremental sync types?
The sync type determines the scope of the sync. It can be one of the following:
Incremental: RudderStack syncs only the newly added data in the warehouse since the last sync.
Full: RudderStack syncs all the data present in the warehouse, irrespective of whether it was synced to the destination previously.
Questions? We're here to help.
Join the RudderStack Slack community or email us for support
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.