Predict user behavior with Propensity Scores in RudderStack Profiles.
18 minute read
This feature is in Beta as part of RudderStack’s Early Access Program, where we work with early users and customers to test new features and get feedback before making them generally available.
Using Profile’s Propensity Scores Data App, you can predict the likelihood of user actions using machine learning (ML) algorithms. These predictive capabilities enable data-driven decision-making by calculating scores that represent the probability of a user performing a specific action within a predefined timeframe, for example:
Is a customer likely to churn in the next 30 days?
Will a user make a purchase in the next 14 days?
Is a lead likely to convert in the next 7 days?
Use cases
Reduced churn: Identify users at risk of churning and implement targeted interventions to retain them.
Increased conversions: Prioritize leads with a higher propensity to convert, boosting your marketing campaign effectiveness.
Improved resource allocation: Focus resources on high-value user segments for maximized impact.
Prerequisites
An active RudderStack Profiles project (v0.18.0 or above) using a Snowflake, BigQuery, or Redshift warehouse.
(Optional) If you are using Snowflake, you might need to create a Snowpark-optimized warehouse if your dataset is significantly large.
Install the profiles-mlcorelib library in your Python environment using pip install profiles-mlcorelib. Note that it should be the same Python environment as the profiles-rudderstack library.
For Redshift and BigQuery: Python versions between 3.9.0 to 3.11.10 are supported.
For Snowflake: Python version must be ≥ 3.9.0 and < 3.11.0.
Update your pb_project.yaml file to include the library:
python_requirements:- profiles_mlcorelib>=0.7.2
Project setup
Follow these steps to set up a propensity model that generates propensity scores within an existing Profiles project:
Step 1: Define the label (prediction target)
Identify and define the action you want to predict (also known as label), for example, inactivity churn, subscription churn, a lead conversion, payer conversion, reactivation, etc.
Suppose you want to predict whether a user will pay for your product. You can create a label named is_payer which takes the value as true for users who have paid and false for those who haven’t.
A sample entity_var definition of is_payer label will be:
entity_var:name:is_payerselect:case when user.revenue > 0 then 1 else 0 end
Label data types
For propensity modeling, the data type must be Boolean or Binary, that is, the label must have only two distinct values like 0/1, true/false, yes/no, etc.
Although not the primary focus on the Propensity model, it can also be used to predict numeric values. In that case the label is a continuous numeric value.
This can be used, for example, for predictions like predicted LTV or predicted purchase total in the next 30 days.
Step 2: Define the relevant entity_vars
You need to specify the user set for model training. For example, you can define following entity_vars that may predict whether a user is likely to spend anything in future:
Some entity_vars may not directly depend on the label and you may not want to train the model on all the users. Define the entity_vars for an eligible user set. For example, to predict a user’s likelihood of paying for a product, define the following features:
New users who created their account within the past 30 days.
Ensure that the entity_vars for features and label originate from input tables with a defined occured_at_col value.
This enables Profiles to correctly materialize past data while considering specific timeframes. Without this, you might get overly optimistic models with misleading metrics.
Step 3: Set the prediction window
Define the time frame within which you want to predict the user behavior. The predict_window_days setting determines this period, for example, you might want to predict churn within the next 30 days.
The value for predict_window_days is use case-dependent. For instance, a daily-use game might benefit from a 7-day churn prediction window, while a monthly subscription service might require a 3-month window.
A sample profiles.yaml with propensity model type and predict_window_days setting:
models:- name:payer_propensity_modelmodel_type:propensitymodel_spec:inputs:- entity/user/days_since_account_creation- entity/user/days_since_last_seen- entity/user/revenue- entity/user/is_payer- entity/user/country- entity/user/n_sessionstraining:predict_var:entity/user/is_payer label_value:1predict_window_days:30eligible_users:days_since_account_creation <= 30 and country = 'US' and revenue = 0
Note that:
All the features and label used by the model (defined as entity_vars), are provided as a list in inputs.
RudderStack appends the value of eligible_users key to an SQL query, forming a query like select * from user_var_table where <eligible_users>. Hence, you must define all the columns used in eligible_users key as entity_vars.
Step 4: Name the predictive features
Specify the features you want to predict within the prediction block. Here’s an example for predicting the payer propensity:
prediction:output_columns:percentile:name:payer_propensity_percentiledescription:Percentile score of a user's likelihood to pay in the next 30 daysscore:name:payer_propensity_probabilitydescription:Probability score of a user's likelihood to pay in the next 30 days
Sample YAML for a predictive feature
After completing the above steps, a complete sample profiles.yaml file for a predictive feature will look as follows:
models:- name:payer_propensity_modelmodel_type:propensitymodel_spec:entity_key:usertraining:predict_var:entity/user/is_payerlabel_value:1predict_window_days:30validity:month type:classification eligible_users:days_since_account_creation <= 30 and country = 'US' and revenue = 0max_row_count:50000warehouse:snowpark_optimised_medium# Optional, only for Snowflake. recall_to_precision_importance:1.0new_materialisations_config:strategy:autofeature_data_min_date_diff:14max_no_of_dates:3dates:- '2024-01-01,2024-01-08'# (feature_date, label_date)- '2024-02-01,2024-02-08'- '2024-03-01,2024-03-08'ignore_features:- country prediction:output_columns:percentile:name:payer_propensity_percentiledescription:Percentile score of a user's likelihood to pay in the next 30 daysscore:name:payer_propensity_probabilitydescription:Probability score of a user's likelihood to pay in the next 30 daysis_feature:Falseeligible_users:'*'# (Optional) Defaults to what's in training.warehouse:snowpark_optimised_small# Optional, only for Snowflake. inputs:- entity/user/days_since_account_creation- entity/user/days_since_last_seen- entity/user/revenue- entity/user/is_payer- entity/user/country- entity/user/n_sessions
You can setup multiple predictive features within the same Profiles project by repeating the whole block for each predictive feature.
The following table explains the fields used in the above file:
Parameter
Description
name Required
Name of the model.
model_type Required
Model type. Set this to propensity.
model_spec Required
Detailed configuration specification for the model.
entity_key Required
Entity to be used.
training Required
Configuration used for training.
predict_var Required
entity_var for which you want make predictions.
label_value Required
Value of label column for which prediction needs to be generated.
predict_window_days Required
Time period within which you want to predict the user behavior.
validity Required
Time period to re-train the model. Allowed values are: day, week, month.
Re-training helps keep the model up-to-date with changing user behavior. But it comes with the cost of increased compute time and resource usage. So its preferable to keep the validity longer (for example, month) if you expect the user behavior doesn’t change too frequently.
type
Tells the model whether you are trying to predict a Boolean feature (for example, yes/no, churned/not_churned, converted/not_converted, etc.), or a numeric feature (for example, amount_spent).
Note that:
The type should be classification if it is a Boolean feature and regression if it is numeric.
If not specified, this parameter defaults to classification - so you can skip this parameter if you are predicting churn, subscription, etc.
eligible_users
User set for model training. RudderStack appends the value of eligible_users key to an SQL query, forming a query like select * from user_var_table where <eligible_users>. Hence, you must define all the columns used in eligible_users key as entity_vars.
If not provided, it defaults to users who have predict_var != label_value during feature generation period, that is, it generates propensity scores for all the users who have not yet converted in the feature generation period.
max_row_count
Maximum number of samples used for ML model training. Default value is 30,000.
Note that:
This parameter only affects sampling when there are more eligible users than this limit. If the number of eligible users is below this threshold, all available samples are used.
This parameter is only an upper limit - the model can train with fewer samples and does not require this many samples to function.
You can use the new_materialisations_config parameter to force the model to use more data points.
warehouse
Optional parameter for Snowflake warehouses only. Specifies a dedicated compute warehouse for ML operations.
Note that:
By default, propensity models use the same warehouse as the main Profiles run. However, since ML training and prediction are compute and memory-intensive processes, you may want to use a Snowpark-optimized warehouse for better performance.
You can configure this parameter independently for both training and prediction sections to use different warehouse sizes for each phase (for example, a larger warehouse for training and a smaller one for prediction).
If not specified, it defaults to the warehouse used by the parent Profiles run.
recall_to_precision_importance
An advanced feature that adjusts the balance between false positives and false negatives in the model’s output. If reducing false positives is more important, set the value closer to 0 (for example, 0.3).
If reducing false negatives is the priority, use a value greater than 1 (for example, 3.0). False positives are costly when it leads to unnecessary actions, such as sending a promo code to loyal users incorrectly identified as at risk of churning. On the other hand, false negatives are more problematic when missing out on targeting someone could lead to a permanent loss, such as a subscription customer who churns and never returns.
If you’re unsure about which to prioritize, you can leave the value at the default of 1.0 (or simply omit the parameter, and the model will automatically set it to 1.0).
new_materialisations_config
This block lets you configure the training data for model in case there is not enough data. See FAQ for more information.
ignore_features
List of entity_var names that are a part of the inputs but should be ignored by the model. This usually happens when your input is a SQL model where there are too many defined features for purposes unrelated to the predictive features.
prediction Required
Configuration used for prediction. It mainly lists the names of output columns and eligible users for whom predictions are to be generated.
output_columns Required
Configuration for output columns to be generated.
percentile Required
Configuration of the column in output table having percentile score.
name Required
Name of the column in output table having percentile score.
description Required
Custom description for the percentile column.
score Required
Configuration of the column in output table having probabilistic score.
name Required
Name of the column in output table having probabilistic score.
description Required
Custom description for the score column.
is_feature Required
If set to False, this feature won’t be available in final C360 table. Defaults to True.
inputs Required
List of input models and entity_vars used by the model.
You must include the label column and vars used in the eligible_users definition here, along with the list of features that the model uses to train.
Note: All inputs of the propensity model must be features.
Step 5: Run your project
After configuring your project, you can run it using one of the following methods:
Using Profile CLI
If you have created your Profiles project locally, run it using the pb run CLI command to generate the output tables.
Once your project run is complete, you can view the following outputs:
Training output
The model generates several outputs based on its training parameters, including charts and a JSON file with metrics. RudderStack stores these artifacts in the outputs folder outputs/seq_no/<seq_no>/run/Material_<model_name><hash>_<seq_no>_reports, for example:
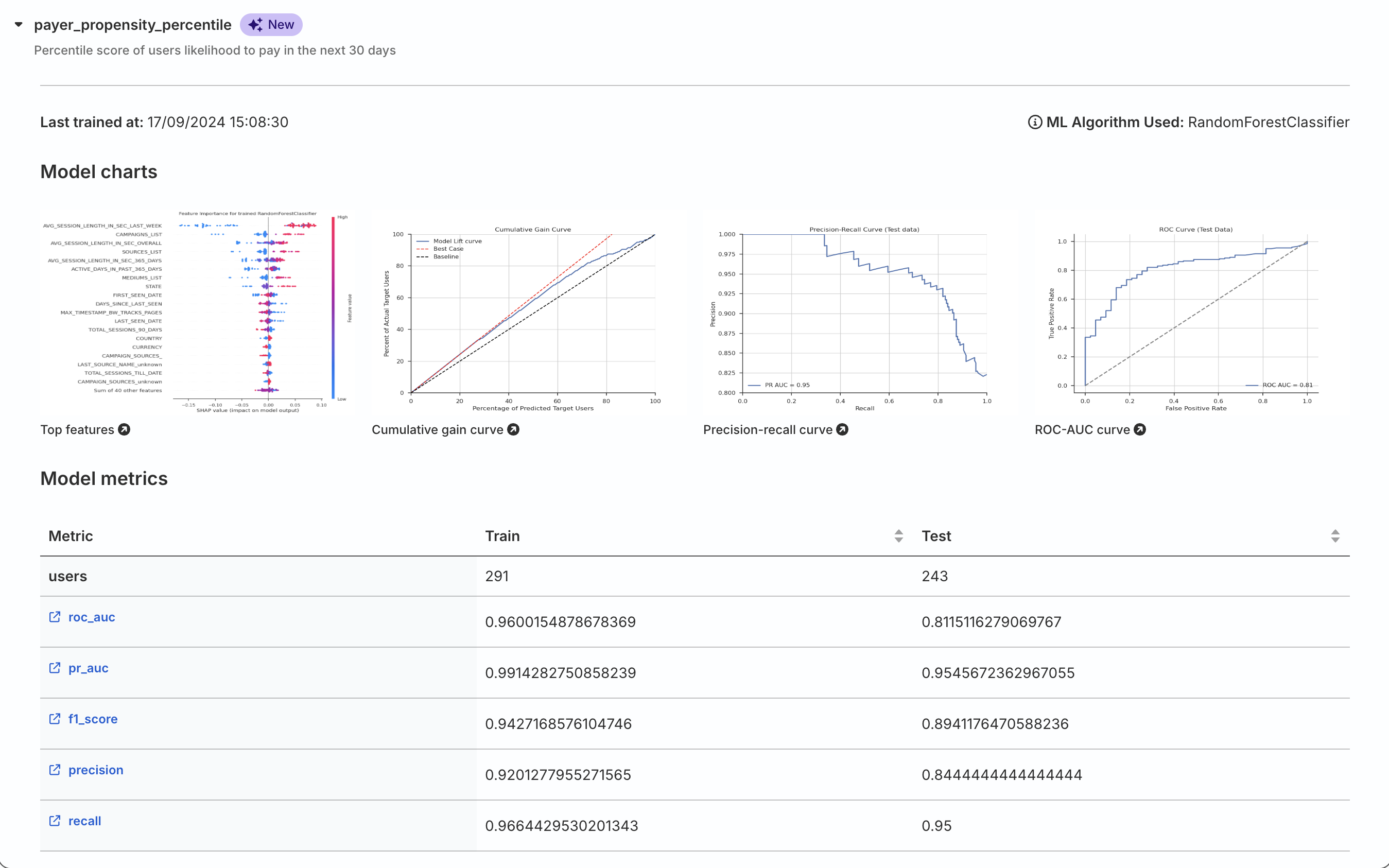
Feature Importance Chart: Highlights the key features influencing predictions.
Cumulative Gain Chart: Provides a visual comparison between the model’s performance and random selection, helping to quantify the model’s ability to identify positive instances efficiently. This chart is particularly useful for optimizing resource allocation in scenarios like marketing campaigns or customer targeting.
Precision-Recall Curve: Assesses the trade-off between precision and recall at various probability thresholds. It is particularly useful for imbalanced datasets, highlighting the model’s ability to identify positive instances while minimizing false positives.
ROC Curve: Assesses the trade-off between true positives and false positives. It helps highlight the model’s ability to separate positive and negative labels.
Additionally, RudderStack writes the metrics from the training_summary.json file to a new row in the TRAINING_METRICS_v4 table in your warehouse.
Prediction output
Based on the prediction parameters, Profiles creates a new table in your warehouse. The table’s name is the same as the model along with a hash and seqence number (for example, Material_payer_propensity_30_days_4dd846le_21).
The table contains the following columns, along with the user_main_id:
Probability score: A value between 0 and 1 indicating the likelihood of a user action, like making a purchase.
Percentile score: A scaled version of the probability score useful for targeting specific user segments, for example, the top 10% for a campaign.
Boolean flag: A true/false indicator of whether a user is likely to perform the action, based on the model’s confidence.
The above columns are essentially the same, only represented in different forms. They represent the same prediction in different formats, catering to various use-cases/levels of granularity and interpretation preferences.
View output
You can either:
View the output materials in your warehouse, OR
If your Profiles project is in the RudderStack dashboard:
Check the predicted value for any given user in the Profile Lookup section.
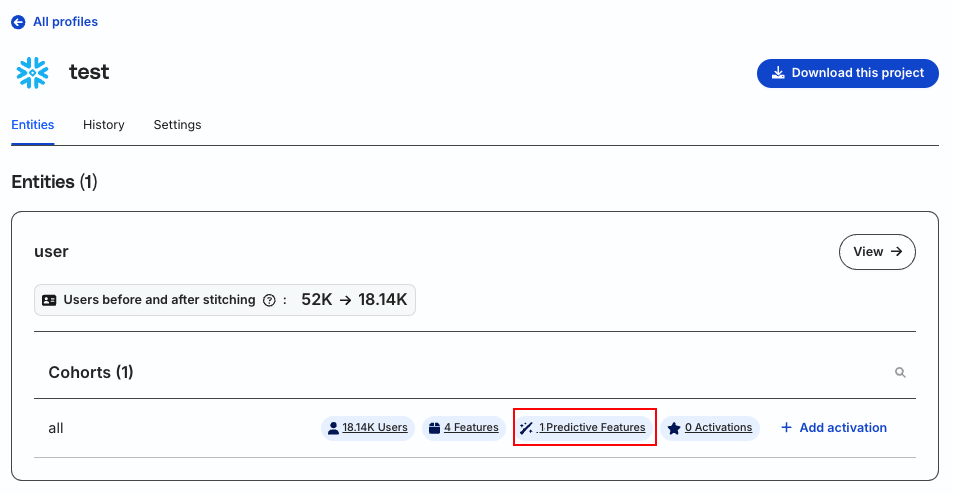
Explore predictive features in the Entities tab of your Profiles project.
Click Predictive features to see the following view:
Use existing feature setup
You can even use an existing feature table set up outside of Profiles (say, any dbt or SQL project) to generate propensity scores. To do so, you need to provide the existing features as inputs via SQL models. The SQL model serves as a wrapper for your feature table.
Note the following specifications for using SQL models:
Define the feature table where original features are defined as an input model. Ensure that the is_event_stream: true, and occurred_at_col is specified. This enables creating feature snapshots at different points in the past. To support this, the feature table should retain the output from old runs as well. As your external pipeline creates new feature table snapshots daily, they should not replace the old data. Ideally, a fresh run should append new data to the same table. But if each job creates a new table, you can union all such tables to create a view. Make sure you have a timestamp column that denotes when the job was run.
The output of the SQL model should have a single row per user.
Ensure that column names in the SQL model are unique even if the SQL models are combined with other input types, such as entity_var.
The SQL model table should already include the entity’s main id column, for example, user_main_id.
Here’s an example to configure SQL models:
# Define the dbt generated feature table in inputs.yamlinputs:- name:rsFeatureTablecontract:is_optional:falseis_event_stream:truewith_entity_ids:- userwith_columns:- name:timestamp- name:user_idapp_defaults:table:user_featuresoccurred_at_col:timestampids:- select:"user_id"type:user_identity:user# Define an id stitcher over this, so the table gets a user_main_id column attachedmodels:- name:rs_id_stitchermodel_type:id_stitchermodel_spec:entity_key:useredge_sources:- from:inputs/rsFeatureTable# Define an SQL model on top of thismodels:- name:rsFeatureTableSnapshotmodel_type:sql_templatemodel_spec:single_sql:| {% with feature_table = this.DeRef("inputs/rsFeatureTable/var_table") entity_id = this.DeRef("inputs/rsTracks/rsFeatureTable/user_main_id") %}
select a.{{entity_id}}, f1, f2, f3 from
(
select * from {{feature_table}} where
timestamp <= '{{end_time.Format(\"2006-01-02 15:04:05\")}}'
) a inner join
(select {{entity_id}}, max(timestamp) as max_timestamp from {{feature_table}} where
timestamp <= '{{end_time.Format(\"2006-01-02 15:04:05\")}}'
group by {{entity_id}}) b on
a.{{entity_id}} = b.{{entity_id}} and a.timestamp = b.max_timestamp
{% endwith %}ids:- select:"user_id"type:user_identity:userto_default_stitcher:truecontract:is_optional:falseis_event_stream:falsewith_entity_ids:- userwith_columns:- name:user_id
FAQ
How does the model select data for training?
For training the ML models, RudderStack needs a minimum of 5000 samples. If the model finds that there fewer than 5000 samples, RudderStack materializes more training data by running the Profiles project at different timestamps in the past. There are two materialization strategies: auto and manual.
auto strategy
The strategy parameter in the new_materialisations_config block specifies the strategy for generating new materials. It is set to auto by default, where the model creates upto 3 pairs of materials (total 6) where each pair is 2 weeks (14 days) apart by default. RudderStack starts with the most recent data, and keeps going back 14 days, till there is enough training data (5000 samples).
Additionally, you can use the below parameters to adjust the default behavior:
max_no_of_dates: Specifies the number of materials to be generated. The default value is 3 pairs.
feature_data_min_date_diff: Specifies the minimum number of days between newly generated materials and existing materials. The default value is 2 weeks (14 days).
Note that the auto strategy may not be able to find enough training data when using the begin_time flag in pb run. If it throws an error saying the data is insufficient, use the manual strategy.
manual strategy
In this case, you can mention the dates from where the training pairs should be generated using the following parameter:
dates: Uses exact dates to generate the feature and label pairs. Make sure these are apart by predict_window_days number of days.
How do I select the eligible_users?
eligible_users is one of the most critical parameters in a propensity model after the label column itself. This parameter defines which users the model should train on. In theory, you could train a model on all users but this often leads to scenarios where stale users - those who haven’t been seen in the app for years - become a part of the training dataset. This causes a “class imbalance problem” in model training. For classification propensity models, the minority label must represent at least 5% of the data.
Without properly configuring the eligible_users parameter, this requirement is likely to be violated, preventing the model from training effectively. Determining appropriate eligible_users criteria depends on your specific use case. The goal is to exclude users who are unlikely to convert within the specified predict_window_days while retaining those who might convert.
For different models, this criteria varies significantly:
For a churn model, you might exclude users who churned long ago and are no longer active.
For a payer propensity model, you might also exclude users who have been active for years but have never made a purchase.
Some common eligible_users conditions include:
Users who have been active within the past few quarters.
Users who signed up or were first seen on the app recently (for example, current month).
Users who demonstrated intent (for example, added items to cart) but did not convert.
Your specific business model and use case will determine the most effective criteria.
Which features should I use as inputs to the model?
RudderStack recommends selecting features that effectively capture user behaviors and characteristics relevant to your prediction target. Focus on including features that represent different aspects of user engagement:
Recency metrics: How recently has the user interacted with your product or service.
Frequency metrics: How often the user engages with key features.
Monetization metrics: Past spending patterns, subscription level, or monetization behaviors.
For specific use cases, consider the following:
For subscription churn prediction: Include features like subscription tenure, feature usage frequency, subscription tier, payment history, and engagement with key product features.
For lead scoring: Focus on features like acquisition source, engagement with pricing or product pages, time spent on site, and interaction with marketing content.
For purchase propensity: Consider cart abandonment history, browsing patterns, past purchase behavior, and response to promotions.
The most effective feature sets typically combine both behavioral data (what users do) and descriptive data (who users are). Experiment with different feature combinations while monitoring the feature importance metrics to refine your approach.
How can I know if the trained model is good?
Although there is no universal good score for model evaluation metrics, here are a few guidelines:
Feature importance: The top features in the feature importance chart should align with your business understanding. Features that unexpectedly appear at the top or important features that are missing might indicate issues with your model.
Cumulative Gain Chart: This chart compares your model’s performance to both a baseline (random selection) and a theoretical best case. If your model’s lift curve is close to the baseline, it indicates underperformance. Conversely, if it approaches the best case line, your model is likely performing well.
ROC-AUC: Scores range from 0.5 (random guessing) to 1.0 (perfect classification). While higher values generally indicate better performance, be cautious with highly imbalanced datasets, which can yield misleadingly high ROC-AUC scores. In these cases, precision metrics are more informative.
Train-Val-Test metrics: Training metrics should be higher than validation/test metrics, but a significant gap suggests overfitting. Ideally, validation and test metrics should be close to each other, indicating the model generalizes well to new data.
If your model’s performance is unsatisfactory, consider these improvement strategies:
Add relevant features: Introduce new features that capture behaviors not represented in your current feature set. The feature importance chart can help identify which types of features are most predictive. Focus on adding features that provide new information rather than those highly correlated with existing features.
Increase training data: If training metrics look promising but the validation metrics are poor, your model may benefit from more training samples. You can adjust the new_materialisations_config to include additional materials by increasing the max_no_of_dates parameter in the auto strategy. This allows the model to incorporate more historical data snapshots.
Questions? We're here to help.
Join the RudderStack Slack community or email us for support
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.