This guide contains solutions for some of the commonly asked questions on Profiles. For queries or issues not listed in this guide, contact RudderStack Support.
Setup and installation
I have installed Python3, yet when I install and execute pb it doesn’t return anything on screen.
Try restarting your Terminal/Shell/PowerShell and try again.
You can also try to find the location of your Python executable. PB would be installed where the executables embedded in other Python packages are installed.
I am an existing user who updated to the new version and now I am unable to use the PB tool. On Windows, I get the error:'pb' is not recognized as an internal or external command, operable program or batch file.
Execute the following commands to do a fresh install:
pip3 uninstall profiles-rudderstack-bin
pip3 uninstall profiles-rudderstack
pip3 install profiles-rudderstack --no-cache-dir
I am unable to download profile builder by running pip3 install profiles-rudderstack even though I have Python installed.
Firstly, make sure that Python3 is correctly installed. You can also try to substitute pip3 with pip and execute the install command.
If that doesn’t work, it’s high likely that Python3 is accessible from a local directory.
Navigate to that directory and try the install command again.
After installation, PB should be accessible from anywhere.
Validate that you’re able to access the path using which pb.
You may also execute echo $PATH to view current path settings.
If echo $PATH does not give you the path, then you can find out where Profiles Builder is installed using pip3 show profiles-rudderstack. This command displays a list of the files associated with the application, including the location in which it was installed. You can navigate to that directory.
Navigate to /bin subdirectory and execute command ls to confirm that pb is present there.
To add the path of the location where PB is installed via pip3, execute: export PATH=$PATH:<path_to_application>. This will add the path to your system’s PATH variable, making it accessible from any directory. It is important to note that the path should be complete and not relative to the current working directory.
If you still face issues, then you can try to install it manually. Contact us for the executable file and download it on your machine. Follow the below steps afterwards:
Move the downloaded file to that directory: sudo mv <name_of_downloaded_file> /usr/local/rudderstack/pb.
Grant executable permission to the file: chmod +x /usr/local/rudderstack/pb.
Navigate to directory /usr/local/rudderstack from your file explorer. Ctrl+Click on pb and select Open to run it from Terminal.
Symlink to a filename pb in /usr/local/bin so that command can locate it from env PATH. Create file if it does not exist: sudo touch /usr/local/bin/pb. Then executesudo ln -sf /usr/local/rudderstack/pb /usr/local/bin/pb.
Verify the installation by running pb in Terminal. In case you get error command not found: pb then check if /usr/local/bin is defined in PATH by executing command: echo $PATH. If not, then add /usr/local/bin to PATH.
If the Windows firewall prompts you after downloading, proceed with Run Anyway.
Rename the executable as pb.
Move the file to a directory, for example, C:\Program Files\Rudderstack. You can create the directory if required.
Set the path of pb.exe file in environment variables.
Verify the installation by running pb in command prompt.
When I try to install Profile Builder tool using pip3 I get error message saying: Requirement already satisfied
Try the following steps:
Uninstall PB using pip3 uninstall profiles-rudderstack.
Install again using pip3 install profiles-rudderstack.
Note that this won’t remove your existing data such as models and siteconfig files.
I am facing this error while ugrading my Profiles project: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. profiles-pycorelib 0.2.2 requires profiles-rudderstack!=0.10.6,<=0.10.7,>=0.10.5, but you have profiles-rudderstack 0.11.0 which is incompatible.
This is because you must uninstall and then reinstall the pycorelib library while upgrading to a recent version.
Warehouse issues
For my Snowflake warehouse, I have two separate roles to read from input tables and write to output tables? How should I define the roles?
You need to create an additional role as a union of those two roles. PB project needs to read the input tables and write the results back to the warehouse schema.
Furthermore, each run is executed using a single role as specified in the siteconfig.yaml file. Hence, it is best in terms of security to create a new role which has read as well as write access for all the relevant inputs and the output schema.
Can I refer a table present in another database within the warehouse?
Snowflake: You can refer tables from cross-database as long as they are in same warehouse.
Bigquery: You can refer tables from cross-projects.
Databricks: You can refer tables from database in the same or another warehouse.
Redshift: For the following setups:
Cluster with DC2 Nodes: You cannot use tables from cross-database in the project.
Cluster with RA3 Nodes/Serverless: You can refer tables from cross-database as long as they are in same warehouse.
While working with Profiles, how can I use the tables in my BigQuery warehouse that are partitioned on the time criteria?
To refer to the partitioned tables in your Profiles project, you must include a filter based on the partitioned column. To do so, add is_event_stream: true and use the partitioned filter as occurred_at_col: timestamp while defining your inputs.yaml file:
I am trying to execute the compile command by fetching a repo via GIT URL but getting this error: making git new public keys: ssh: no key found
You need to add the OpenSSH private key to your siteconfig.yaml file. If you get the error could not find expected afterwards, try correcting the spacing in your siteconfig.yaml file.
While trying to segregate identity stitching and feature table in separate model files, I am getting this error: mapping values are not allowed in this context
This is due to the spacing issue in siteconfig.yaml file. You may create a new project to compare the spacing. Also, make sure you haven’t missed any keys.
While using v0.13, I notice that two subfolders are created inside the output folder for compile and run, even if I execute only the pb run command. What exactly is the difference between them?
RudderStack generates two subfolders for easy debugging as compiling is a substep of running the project. If you encounter an error during the project run and are not able to get the corresponding SQL generated for this step, you can still rely on the SQL generated during the compile step to debug the error.
I want to build profiles over my Snowflake warehouse data which is pulled in using Salesforce (CRM tool). Is it necessary that the data in my Snowflake warehouse flows via RudderStack? Can I build an entity model for Salesforce users that references the Snowflake table?
RudderStack Profiles lets you use any data present in your warehouse. It does not need to come in via RudderStack. Further, you can define the entities in a pb_project.yaml file and use them declaratively while describing the columns of your input sources.
Command progress & lifecycle
I executed a command and it is taking too long. Is there a way to kill a process on data warehouse?
It could be due to the other queries running simultaneously on your warehouse. For example, for the Snowflake warehouse, open the Queries tab and manually kill the long running processes.
Due to the huge data, I am experiencing long execution times. My screen is getting locked, thereby preventing the process from getting completed. What can I do?
You can use the screen command on UNIX/MacOS to detach your screen and allow the process to run in the background.
You can use your terminal for other tasks, thus avoiding screen lockouts and allowing the query to complete successfully.
Here are some examples:
To start a new screen session and execute a process in detached mode: screen -L -dmS profiles_rn_1 pb run. Here:
-L flag enables logging.
-dmS starts as a daemon process in detached mode.
profiles_rn_1 is the process name.
To list all the active screen sessions: screen -ls.
To reattach to a detached screen session: screen -r [PID or screen name].
The CLI was running earlier but it is unable to access the tables now. Does it delete the view and create again?
Yes, every time you run the project, Profiles creates a new materials table and replaces the view.
Hence, you need to grant a select on future views/tables in the respective schema and not just the existing views/tables.
Does the CLI support downloading a git repo using siteconfig before executingpb run? Or do I have to manually clone the repo first?
You can pass the Git URL as a parameter instead of project’s path, as shown:
pbrun-pgit@.....
When executingruncommand, I get a message:Please use sequence number ... to resume this project in future runs. Does it mean that a user can exit using Ctrl+C and later if they give this seq_no then it’ll continue from where it was cancelled earlier?
The pb run --seq_no <> flag allows for the provision of a sequence number to run the project. This flag can either resume an existing project or use the same context to run it again.
With the introduction of time-grain models, multiple sequence numbers can be assigned and used for a single project run.
What flag should I set to force a run for the same input data (till a specified timestamp), even if a previous run exists?
You can execute pb run --force --model_refs models/my_id_stitcher,entity/user/user_var_1,entity/user/user_var_2,...
Can the hash change even if schema version did not change?
Yes, as the hash versions depends on project’s implementation while the schema versions are for the project’s YAML layout.
Is there a way to pick up from a point where my last pb run failed on a subsequent run? For large projects, I don’t want to have to rerun all of the features if something failed as some of these take several hours to run
Yes, you can just execute the run command with the specific sequence number, for example, pb run —seq_no 8.
What is the intent of pb discover models and pb discover materials command?
You can use pb discover models to list all the models from registry and pb discover materials to list all the materials from the registry.
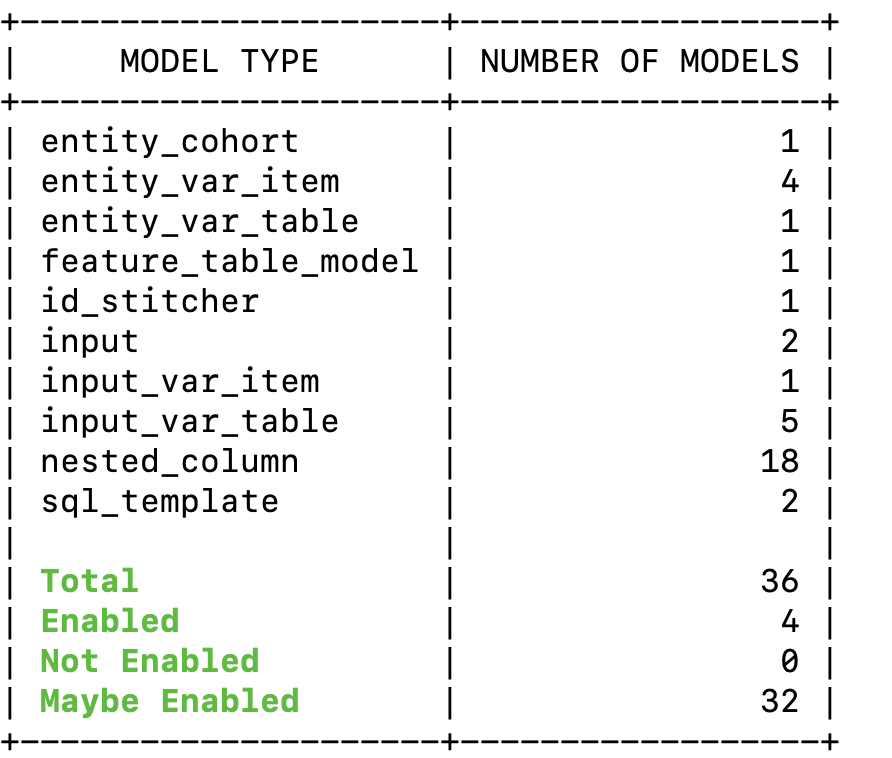
I got this while running pb show models. What is “Maybe Enabled”?
In the show models command, the enable status is computed without looking at tables in the warehouse. Imagine a modelM that has an optional input column. So, M is enabled if and only if the optional input column is present. Hence, it may or may not be enabled, depending on whether the input column is present or not.
How can I handle my Profiles project in the development and production workspace in RudderStack?
Profiles support git branches in the RudderStack dashboard. Refer Supported Git URLs for more information.
In case you wish to run only one project in the CLI and run them differently in dev and prod, you can use targets:
Create a connection using pb init connection and give a connection name (say test). Then, give a default target name, say prod. Enter remaining details.
Create another connection using pb init connection and give the same connection name as before (test). Then, give a different target name, say dev. Enter remaining connection details for connecting to your warehouse.
When you execute a command via CLI, you need to pass -t flag. The first connection you’ve defined is the default one, hence, you don’t need to pass a flag explicitly. However, you can pass it for the other one. For example, pb run -t dev.
Targets aren’t yet supported in the UI. So while you can run the same project on different instances (prod, dev) in the CLI; in the UI you have to make either a different project or a different branch/tag/subfolder.
I am getting an “operation timed out” error even though the pb validate access command worked fine.
Retry the command run after some time. It should resolve the issue.
I have defined a version constraint in my project and migrated it to the latest schema using pb migrate auto command. The project is migrated except the python_requirements key which has the same version constraints. How do I change that?
You need to manually change the project version in CLI as the version constraints don’t change automatically.
How can I generate the .sql output file for my Profiles project containing sql_models.yaml. It is currently not getting generated because the SQL model is not used anywhere.
Even if your SQL model is not used anywhere, you can generate the .sql output file in the warehouse by ensuring that:
Your model’s output_type is not set to ephemeral. Removing the materialization section from the model_spec and observe the outputs.
Your model’s requested_enable_status is not set to only_if_needed.
Identity stitching
There are many large size connected components in my warehouse. To increase the accuracy of stitched data, I want to increase the number of iterations. Is it possible?
The default value of the largest diameter, that is, the longest path length in connected components, is 30.
You can increase it by defining a max_iterations key under model_spec of your ID stitcher model in models/profiles.yaml, and specifying its value as the max diameter of connected components.
Note that the algorithm can give incorrect results in case of large number of iterations.
Do I need to write different query each time for viewing the data of created tables?
No, you can instead use a view name, which always points to the latest created material table. For example, if you’ve defined user_stitching in your models/profiles.yaml file, then execute SELECT * FROM MY_WAREHOUSE.MY_SCHEMA.user_stitching.
I want to use customer_id instead of main_id as the ID type. So I changed the name in pb_project.yaml, however now I am getting this error: Error: validating project sample_attribution: listing models for child source models/: error listing models: error building model domain_profile_id_stitcher: main id type main_id not in project id types.
In addition to making changes in the file pb_project.yaml file, you also need to set main_id_type: customer_id in the models/profiles.yaml file.
If a user account (user_id) is deleted, will the associated user_main_id be deleted as well?
If a user_id is not found in the input sources, it would not be tied to that user_main_id after a full run. However, the user_main_id would still exist if the first node was from an anonymousId for that user.
Suppose a user_main_id has two associated user_ids as they share the same phone number. If one of the user_id changes their phone number, will the user_main_id be updated to include only one of the user_ids? Will a new user_main_id be created for the other user_id?
In this case, as the common node (phone number) is removed, after a full run, the two users would not be associated to the same user_main_id and a new user_main_id would be created for the other user.
I ran identity stitching model but not able to see the output tables under the list of tables in Snowflake. What might be wrong?
In Snowflake, you can check the Databases > Views dropdown from the left sidebar. For example, if your model name is domain_profile_id_stitcher, you should be able to see the table with this name. In case it is still not visible, try changing the role using dropdown menu from the top right section.
I am using a view as an input source but getting an error that the view is not accessible, even though it exists in DB.
Views need to be refreshed from time-to-time. You can try recreating the view in your warehouse and also execute a select * on the same.
What might be the reason for following errors:
processing no result iterator: pq: cannot change number of columns in view.
The output view name already exists in some other project. To fix this, try dropping the view or changing its name.
creating Latest View of moldel 'model_name': processing no result iterator: pq: cannot change data type of view column "valid_at"
Drop the view domain_profile in your warehouse and execute the command again.
processing no result iterator: pq: column "rudder_id" does not exist.
This occurs when you execute a PB project with a model name, having main_id in it, and then you run another project with the same model name but no main_id. To resolve this, try dropping the earlier materials using cleanup materials command.
I have a source table in which email gets stored in the column for user_id, so the field has a mix of different ID types. I have to tie it to another table where email is a separate field. When doing so, I have two separate entries for email, as type email and user_id. What should I do?
You can implement the following line in the inputs tables in question:
- select:case when lower(user_id) like '%@%' THEN lower(user_id) else null endtype:email entity:userto_default_stitcher:true
How do I validate the results of identity stitching model?
Which identifiers would you recommend that I include in the ID stitcher for an ecommerce Profiles project?
We suggest including identifiers that are unique for every user and can be tracked across different platforms and devices. These identifiers might include but not limited to:
Email ID
Phone number
Device ID
Anonymous ID
User names
These identifiers can be specified in the file profiles.yaml file in the identity stitching model.
Remember, the goal of identity stitching is to create a unified user profile by correlating all of the different user identifiers into one canonical identifier, so that all the data related to a particular user or entity can be associated with that user or entity.
If I run --force with an ID Stitcher model and also pass a --seq_no for the most recent run, will it still recreate the full ID Graph? Also, is there a way to know if the model was run incrementally or not?
This will re-run the ID stitcher and if it is incremental, it will look for the most recent run of the stitcher. After finding the existing run for that seq_no, it will use it as the base. This is because the base for an incremental run could be the current seq_no. If you do not want to do this, you can pass the rebase_incremental flag.
What is difference between valid_at and first_seen_at in the ID graph?
In the context of the ID Stitcher output, the columns valid_at and first_seen_at serve to capture the timestamps for each record related to the edges and clusters created during the connected component analysis.
valid_at: Represents the timestamp at which a particular edge or cluster association is considered valid. It is generally derived from the minimum timestamp in the source data (as seen in the insert_input_edges macro), meaning it is the earliest known point at which this association was active or could be recognized. For example, if two nodes became connected due to an event on 2024-01-01, valid_at for this edge would be 2024-01-01.
first_seen_at: Indicates the first time that a particular node was observed in the context of its current cluster. It is populated with the valid_at timestamp initially but may get adjusted to represent the earliest time at which a specific node became part of the identified cluster, especially when merging nodes or edges into the cluster during subsequent processing. This is seen in the propogate_ids_step and prune_mapping_select_statement macros, where first_seen_at can be recalculated as nodes are merged.
Consider a situation where Node A and Node B are first linked on 2024-01-01. Both valid_at and first_seen_at for this cluster association would be 2024-01-01.
Later, Node C is connected to this cluster on 2024-02-15. Here, valid_at for Node C in this cluster might be 2024-02-15, reflecting the earliest time this connection was valid, but first_seen_at for Node C’s presence in the overall cluster could be 2024-01-01, inherited from the earliest presence of Node A and Node B.
In summary:
valid_at marks when each connection or node-cluster relationship is valid in the data.
first_seen_at records the earliest known appearance of a node in its cluster, potentially adjusted as new connections are processed.
This differentiation ensures a clear lineage for each node within its cluster over time, tracking both its initial and current validity in the analysis.
I am getting a bunch of NULL VALID_AT timestamps. Is it because the table where the data is being referenced from does not have a timestamp fields specified? Will this impact anything in the downstream?
Yes, if there is no timestamp field in the input table (or it is NULL for the row from where the edge source was pulled), then VALID_AT column would have NULL value. This only affects the VALID_AT column in the final table and nothing in the ID stitching.
Which identifiers should I include in my inputs.yaml file?
Include all the IDs that contribute to the ID stitcher model.
Should I re-run the stitching process once all user_id’s have been sorted out with market prefixes? I want to ensure that users are captured separately instead of being grouped under one rudder_id.
It is recommended to use the --rebase-incremental flag and re-run the stitching process from scratch. While it may not be necessary in all cases, doing so ensures a fresh start and avoids any potential pooling of users under a single rudder_id. It’s important to note that if you make any changes to the YAML configuration, such as modifying the entity or model settings, the model’s hash will automatically update. However, some changes may not be captured automatically (for example, if you didn’t change YAML but simply edited column values in the input table), so manually rebasing is a good practice.
While running my ID stitcher model, I get the error “Could not find parent table for alias “”
This is because RudderStack tries to access the cross-database objects (views/tables) for inputs, which is only supported on Redshift RA3 node type clusters.
To resolve the issue, you can upgrade your cluster to RA3 node type or copy data from source objects to the database specified in the siteconfig file.
I want to use a SQL model for an exclusion filter which references tables that are not used in the ID stitching process. Do I still need to add those tables to the inputs.yaml file?
It is not necessary to add the table references to the inputs.yaml file. However, it is advised to add it for the following reasons:
You can rule out any access/permissions issues for the referenced tables.
The contract field in inputs.yaml would help you handle errors if the required column doesn’t exist.
In my Profiles project, I am making changes to cohorts and var groups and triggering the run one after another. Will the ID stitcher model run every time?
Every time you trigger the project run:
The ID stitcher model runs unless you choose to run only specific models. In that case, only the specified models and their dependencies run unless they already exist.
Models with specified timegrains do not run again within the same time grain.
If you re-use the previous sequence number, the project run will resume the previous invocation and will not recreate the materials that got created previously.
I have provided around 50M ID types as inputs to my ID stitching model but the output is converging to a single user. What might be the reason?
That might happen due to the following reasons:
The identifiers you’re using might not be unique for each user, causing the ID graph to converge into one entity. Make sure that they are unique.
Sometimes, false edges are added to the ID graph if there is any user ID value that should have been ignored. You can exclude these entity ID values by listing them in the id_types declaration in the pb_project.yaml file:
Is it possible to define two ID stitcher models in a single Profiles project?
Yes, you can define different entities and an ID Stitcher model for each entity in your Profiles project.
Feature Table (deprecated)
How can I run a feature table without running its dependencies?
Suppose you want to re-run the user entity_var days_active and the rsTracks input_var last_seen for a previous run with seq_no 18.
Then, execute the following command:
pb run --force --model_refs entity/user/days_active,inputs/rsTracks/last_seen --seq_no 18
I have imported a library project but it throws an error: no matching model found for modelRef rsTracks in source inputs.
You can exclude the missing inputs of the library project by mapping them to nil in the pb_project.yaml file.
Can I run models which consider the input data within a specified time period?
Yes, you can do so by using the begin_time and end_time parameters with the run command. For example, if you want to run the models for data from 2nd February, 2023, use:
$ pb run --begin_time 2023-01-02T12:00:00.0Z
If you want to run the nmodels for data between 2 May 2022 and 30 April 2023, use:
$ pb run --begin_time 2022-05-01T12:00:00.0Z --end_time 2023-04-30T12:00:00.0Z
If you want to run the models incrementally (run them from scratch ignoring any previous materials) irrespective of timestamp, use:
$ pb run --rebase_incremental
Is it possible to run the feature table model independently, or does it require running alongside the ID stitcher model?
You can provide a specific timestamp while running the project, instead of using the default latest time. PB recognizes if you have previously executed an identity stitching model for that time and reuses that table instead of generating it again.
You can execute a command similar to: pb run --begin_time 2023-06-02T12:00:00.0Z --end_time 2023-06-03T12:00:00.0Z. Note that:
To reuse a specific identity stitching model, the timestamp value must match exactly to when it was run.
If you have executed identity stitching model in the incremental mode and do not have an exact timestamp for reusing it, you can select any timestamp greater than a non-deleted run. This is because subsequent stitching takes less time.
To perform another identity stitching using PB, pick a timestamp (for example, 1681542000) and stick to it while running the feature table model. For example, the first time you execute pb run --begin_time 2023-06-02T12:00:00.0Z --end_time 2023-06-03T12:00:00.0Z, it will run the identity stitching model along with the feature models. However, in subsequent runs, it will reuse the identity stitching model and only run the feature table models.
While trying to add a feature table, I get an error at line 501, but I do not have these many lines in my YAML.
The line number refers to the generated SQL file in the output folder. Check the console for the exact file name with the sequence number in the path.
While creating a feature table, I get this error:Material needs to be created but could not be: processing no result iterator: 001104 (42601): Uncaught exception of type 'STATEMENT ERROR': 'SYS _W. FIRSTNAME' in select clause is neither an aggregate nor in the group by clause.
This error occurs when you use a window function any_value that requires a window frame clause. For example:
Is it possible to create a feature out of an identifier? For example, I have a RS user_main_id with two of user_ids stitched to it. Only one of the user_ids has a purchase under it. Is it possible to show that user_id in the feature table for this particular user_main_id?
If you know which input/warehouse table served as the source for that particular ID type, then you can create features from any input and also apply a WHERE clause within the entity_var.
For example, you can create an aggregate array of user_id’s from the purchase history table, where total_price > 0 (exclude refunds, for example). Or, if you have some LTV table with user_id’s, you could exclude LTV < 0.
Is it possible to reference an input var in another input var?
Yes - input vars are similar to adding additional columns to the original table. You can use an input var i1v1 in the definition of input var i1v2 as long as both input vars are defined in the same input (or SQL model) i1.
I have not defined any input vars on I1. Why is the system still creating I1_var_table?
When you define an entity var using I1, an internal input var (for entity’s main_id) is created which creates I1_var_table. RudderStack team is evaluating whether internal input vars should create the var table or not.
I have an input model I1. Why is the system creating Material_I1_var_table_XXXXXX_N?
This material table is created to keep the input vars defined on I1.
I am trying to run a single entity_var model. How should I reference it?
The right way to reference an entity var is: entity/<entity-name>/<entity-var-name>.
I have two identical named fields in two user tables and I want my Profiles project to pick the most recently updated one (from either of the user tables). What is the best way to do it?
Define different entity_vars (one for each input) and then pick the one with a non-null value and higher priority.
What does running material mean?
It means that the output (material) table is being created in your warehouse. For example, an output table named material_user_id_stitcher_3acd249d_21 would mean:
material: Prefix for all the objects created by Profiles in your warehouse, such as ID stitcher and feature tables.
user_id_stitcher: View created in your schema. It will always point to latest ID stitcher table. This name is the same as defined in the models/profiles.yaml file.
3acd249d: Unique hash which remains the same for every model unless you make any changes to the model’s config, inputs or the config of model’s inputs.
21: Sequence number for the run. It is a proxy for the context timestamp. Context timestamp is used to checkpoint input data. Any input row with occured_at timestamp value greater than the context timestamp cannot be used in the associated run.
YAML
Are there any best practices I should follow when writing the PB project’s YAML files?
Also, if have a case statement, then you can add something like the following:
select: CASE WHEN {{user.Var("max_timestamp_tracks")}}>={{user.Var("max_timestamp_pages")}} THEN {{user.Var("max_timestamp_tracks")}} ELSE {{user.Var("max_timestamp_pages")}} END
Is it possible to define default arguments in macros?
No, RudderStack does not support default arguments in macros.
ML/Python Models
Despite deleting WhtGitCache folder and adding keys to siteconfig, I get this error:Error: loading project: populating dependencies for project:base_features, model: churn_30_days_model: getting creator recipe while trying to get ProjectFolder: fetching git folder for git@github.com:rudderlabs/rudderstack-profiles-classifier.git: running git plain clone: repository not found. What might be the reason?
If your token is valid, then replace git@github.com:rudderlabs/rudderstack-profiles-classifier.git with https://github.com/rudderlabs/rudderstack-profiles-classifier.git in the profile-ml file.
Why is my Profiles project taking so long to run?
The first Profiles project run usually takes longer, especially if you are building predictive features.
I am debugging an error in ML models where I see a view with the model name, without material/hash prefix and suffix but it does not get refreshed even after all the entity vars are created and the material_<feature_table_model> table is also created. What might be the reason?
It is because this view is now moved to PostProjectRunCb, meaning, it is created async after material Force run step.
Activation API
While using Redis destination, I am facing an error: These sample records were rejected by the destination?
This error is observed if you have enabled Cluster mode setting for Redis in the RudderStack’s configuration settings but you are on the Redis free plan.
To overcome this, ensure that the Redis plan you are using allows clustering. Alternatively, you can turn off the Cluster mode setting.
Does the user-profiles API (old) and activation API (new) behave differently in updating a key that maps to two different primary keys? For example:
Primary key
user_id
Feature_1
Feature_2
PK1
U1
F1
null
PK2
U1
null
F2
Yes, in user profiles API, RudderStack updates the value for a specific key (that is, feature_1 in this case):
Is it possible to use the Activation API without any Profiles project?
Unfortunately, no! The Activation API works only with a Profiles project.
I have toggled on the Activation API option in the RudderStack dashboard to generate a Reverse ETL pipeline (connected to the Redis destination) and have defined a single ID in the feature_views key. However, two Reverse ETL pipelines are generated on running the project. Which one should I use and what is the difference between the two?
Profiles generates two feature_views models if you define a single ID under the feature_views key. One is the default feature view with main_id as the identifier and the other is based on the identifier you have defined.
RudderStack assigns the default names to the view such as user_feature_view (default one with main_id as the identifier), or feature_view_with_email (email as the identifier), etc. You can also specify the final view’s name in the name key.
Profiles UI
I have included some features in the RudderStack dashboard while creating the Profiles project but when I click “download this project”, my project files does not include any feature. What might be the reason?
If you have selected pre-defined features from any library project, they are referred to as profiles-multieventstream-features in the project by default.
If you have created any features using the custom feature functionality, they will be a part of your models/resources.yaml file.
While choosing pre-defined features in the RudderStack dashboard, I can preview code for only some of the features. What might be the reason?
You can preview the code only for entity var based features. This functionality is not available for features built from ML and SQL models.
While creating a Profiles project by importing from Git, I dont see any warehouse options in the dropdown selector in the Validate Profiles project section. What might be the reason?
A Profiles project looks for the supported warehouse destinations configured for that workspace. Hence, make sure you have configured any of the following warehouse destinations in your RudderStack dashboard:
Snowflake
Databricks
Redshift
BigQuery
Why am I not able to see the Concurrency option in the Settings tab of my Profiles project?
RudderStack supports the Concurrency option only for the Snowflake warehouse currently. You will not be able to see this option if you have configured your Profiles project using the Redshift, BigQuery, or Databricks warehouse.
I have chosen some pre-defined predictive features while creating a Profiles project in the RudderStack dashboard but my project fails on running. What might be the reason?
One of the probable reasons could be the lack of adequate data in your input source. Try following the steps suggested in the error message. In case the issue still persists, contact our support team.
I am creating an activation in the RudderStack dashboard but do not see the ID field being populated. What might be the reason?
To populate the IDs in the dropdown, make sure that your Profiles project has feature_views defined in the pb_project.yaml file under the entity.
Can I specify any git account like CommitCode while configuring a project in the web app?
Profiles UI supports repos hosted on GitHub, BitBucket and GitLab.
Miscellaneous
Why am I getting Authentication FAILED error on my data warehouse while executing the run/compile commands?
Some possible reasons for this error might be:
Incorrect warehouse credentials.
Insufficient user permissions to read and write data. You can ask your administrator to change your role or grant these privileges.
Why am I getting Object does not exist or not authorized error on running this SQL query: SELECT * FROM "MY_WAREHOUSE"."MY_SCHEMA"."Material_domain_profile_c0635987_6"?
You must remove double quotes from your warehouse and schema names before running the query, that is SELECT * FROM MY_WAREHOUSE.MY_SCHEMA.Material_domain_profile_c0635987_6.
Is there a way to obtain the timestamp of any material table?
Yes, you can use the GetTimeFilteringColSQL() method to get the timestamp column of any material. It filters out rows based on the timestamp. It returns the occurred_at_col in case of an event_stream table or valid_at in case the material has that column. In absense of both, it returns an empty string. For example:
What is the difference between setting up Profiles in the RudderStack dashboard and Profile Builder CLI tool?
You can run Profiles in the RudderStack dashboard or via Profile Builder CLI.
The main difference is that the RudderStack dashboard only generates outputs based on the pre-defined templates. However, you can augment those outputs by downloading the config file and updating it manually.
On the other hand, the CLI tool lets you achieve the end-to-end flow via creating a Profile Builder project.
Does the Profiles tool have logging enabled by default for security and compliance purposes?
Logging is enabled by default for nearly all the commands executed by CLI (init, validate access, compile, run, cleanup, etc.). Logs for all the output shown on screen are stored in the file logfile.log in the logs directory of your project folder. This includes logs for both successful and failed runs. RudderStack appends new entries at the end of the file once a command is executed.
Some exceptions where the logs are not stored are:
query: The logger file stores the printing output and does not store the actual database output. However, you can access the SQL queries logs in your warehouse.
help: For any command.
How can I remove the material tables that are no longer needed?
To clean up all the materials older than a specific duration, for example 10 days, execute the following command:
pb cleanup materials -r 10
The minimum value you can set here is 1. So if you have run the ID stitcher today, then you can remove all the older materials using pb cleanup materials -r 1.
Which tables and views are important in Profiles schema that should not be deleted?
material_registry
material_registry_<number>
pb_ct_version
ptr_to_latest_seqno_cache
wht_seq_no
wht_seq_no_<number>
Views whose names match your models in the YAML files.
Material tables from the latest run (you may use the pb cleanup materials command to delete materials older than a specific duration).
I executed the auto migrate command and now I see a bunch of nestedoriginal_project_folder. Are we migrating through each different version of the tool?
This is a symlink to the original project. Click on it in the Finder (Mac) to open the original project folder.
I am getting a ssh: handshake failed error when referring to a public project hosted on GitHub. It throws error for https:// path and works fine for ssh: path. I have set up token in GitHub and added to siteconfig.yaml file but I still get this error.
You need to follow a different format for gitcreds: in siteconfig. See SiteConfiguration for the format.
After changing siteconfig, if you still get an error, then clear the WhtGitCache folder inside the directory having the siteconfig file.
If I add filters toid_typesin the project file, then do all rows that include any of those values get filtered out of the analysis, or is it just the specific value of that id type that gets filered?
The PB tool does not extract rows. Instead, it extracts pairs from rows.
So if you had a row with email, user_id, and anonymous_id and the anonymous_id is excluded, then the PB tool still extracts the email, user_id edge from the row.
In the material registry table, what doesstatus: 2mean?
status: 2 means that the material has successfully completed its run.
status: 1 means that the material did not complete its run.
I am using Windows and get the following error:Error: while trying to migrate project: applying migrations: symlink <path>: A required privilege is not held by the client.
Your user requires privileges to create a symlink. You may either grant extra privileges to the user or try with a user containing Admin privileges on PowerShell. In case that doesn’t help, try to install and use it via WSL (Widows subsystem for Linux).
If I want to run multiple select models, how can I run something like: pb run --model_refs "models/ewc_user_id_graph_all, models/ewc_user_id_graph, models/ewc_user_id_graph_v2
You can do so by passing --model_refs multiple times per model:
pb run -p samples/test_feature_table --model_refs 'models/test_id__, user/all' --migrate_on_load
OR
pb run -p samples/test_feature_table --model_refs models/test_id__ --model_refs user/all --migrate_on_load
How can I keep my Profiles projects up to date along with updating the Python package and migrating the schema version?
You can check for the latest Profiles updates in the changelog.
To update the Python package and migrate the schema version, you can standardise on a single pip release across the org and use the schema version that is native to that binary. When you move to a different binary, migrate your projects to the schema version native to it.
Contact Profiles support team in our Community Slack for specific questions.
I am facing this error on adding a custom ID visitor_id under the id_types field in the pb_project.yaml file:could not create project: failed to read project yaml Error: validating project sample_attribution: getting models for folder: user: error listing models: error building model user_default_id_stitcher: id type visitor_id not in project id types. What might be the reason?
While adding a custom ID type, you must extend the package to include its specification in the pb_project.yaml file as well. In this case, add the key extends: followed by name of the same/different id_type that you wish to extend, and corresponding filters with include/exclude values like below:
Yes, you can create multiple folders in your project repo and keep different projects in each folder. While running the project, you can use any suitable URL to run a specific project:
Activations qualify as Audiences with a minor exception of having a Profiles project as a source instead of a Reverse ETL source (with schema, database, table etc).
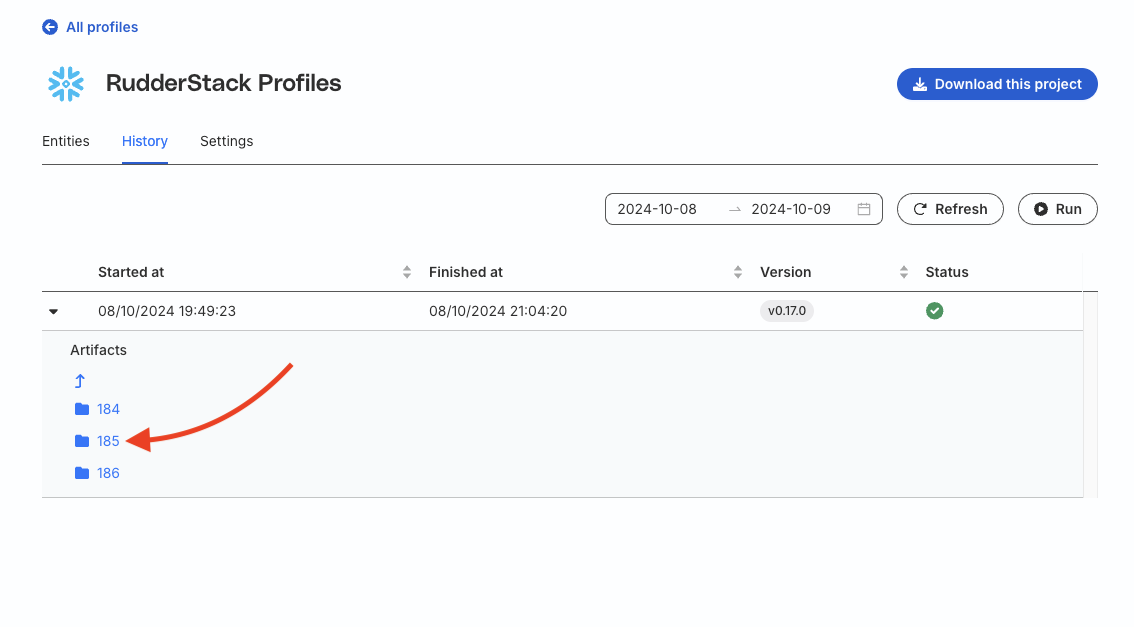
What do the sequence numbers under Artifacts in the History tab mean?
A unique sequence number is generated every time you run a Profiles project. Each project run generates one sequence number. However, note that defining timegrains can result in multiple sequence numbers (based on the timegrain).
I am running a Profiles project with the timegrains parameter and noticed that multiple subfolders having different seq_no are generated. Which seq_no should I use to resume an earlier run?
For the CLI project, you can resume the project run using CLI commands(like run, compile, etc.) and passing the --seq_no displayed at the top of the terminal output. For the UI project, you cannot choose to stop/resume the project run.
What is the purpose of the PTR_TO_LATEST_SEQNO_CACHE view in a Profiles schema?
The PTR_TO_LATEST_SEQNO_CACHE view scans the registry to build metadata for finding the latest table or view of any model name or model hash. This metadata then goes into the creation of views named model - for each model named model - and points to the latest Material_model_xxxxxxxx_n after every run.
I have multiple models in my project. Can I run only a single model?
Yes, you can. In your spec YAML file for the model you don’t want to run, set materialization to disabled:
materialization:enable_status:disabled
A sample profiles.yaml file highlighted a disabled model:
models:- name:test_sqlmodel_type:sql_templatemodel_spec:materialization:run_type:discreteenable_status:disabled // Disables running the model.single_sql:| {%- with input1 = this.DeRef("inputs/tbl_a") -%}
select id1 as new_id1, {{input1}}.*
from {{input1}}
{%- endwith -%}occurred_at_col:insert_tsids:- select:"new_id1"type:test_identity:user
Why am I getting the error could not build project from package corelib: getting ProjectFolder: getting tags list: repository not found?
It might be due to a change in your git credentials. Try resetting them in your system configuration and try again.
What factors should I consider while defining the edge sources for my user ID graph?
The ID graph needs only a minimum set of inputs for capturing all the identifiers. For example, you might not need to include the tracks table to just capture the client side track calls. As the anonymous_ids, user_ids, and emails are probably captured in the pages and identifies tables.
Why is my Profiles project run failing since I enabled SAML SSO on GitHub?
My Profiles project run is failing since I enabled SAML SSO on GitHub. What might be the reason?
After enabling SSO on GitHub, you must edit your Profiles project and deploy the updated SSH key. Also, make sure you are logged in to GitHub using SSO while doing that.
This site uses cookies to improve your experience while you navigate through the website. Out of
these
cookies, the cookies that are categorized as necessary are stored on your browser as they are as
essential
for the working of basic functionalities of the website. We also use third-party cookies that
help
us
analyze and understand how you use this website. These cookies will be stored in your browser
only
with
your
consent. You also have the option to opt-out of these cookies. But opting out of some of these
cookies
may
have an effect on your browsing experience.
Necessary
Always Enabled
Necessary cookies are absolutely essential for the website to function properly. This
category only includes cookies that ensures basic functionalities and security
features of the website. These cookies do not store any personal information.
This site uses cookies to improve your experience. If you want to
learn more about cookies and why we use them, visit our cookie
policy. We'll assume you're ok with this, but you can opt-out if you wish Cookie Settings.