History of data collection
The world we live in today is driven by data. From personalized product recommendations to predictive analytics, data is at the heart of modern innovation. But did you know that data collection and analysis have been around for thousands of years, in various forms? From the invention of writing to the development of the modern computer, the history of data is a fascinating journey through human ingenuity and innovation.
In this article, we will take you on a captivating journey through the history of data, starting from ancient times to the emergence of modern data science and machine learning. We will explore pivotal moments in data collection and analysis that have shaped the course of human history. By tracing the evolution of data over time, we can gain a better appreciation for the impact it has had on science, technology, and society as a whole.
References for all the facts and figures can be found at the end of this article.
Early data

Clay Tablet
The history of data can be traced back to the ancient world. Evidence of early data collection dates back to the earliest known human civilizations. For example, ancient Sumerians, who lived in what is now modern-day Iraq, kept written records of harvests and taxes on clay tablets over 5,000 years ago [1].
The evolution of writing helped shape data collection, as written records became more widespread and sophisticated. Libraries, which first appeared in ancient Egypt around 2,000 BCE, were instrumental in the curation and preservation of written records. The earliest libraries were typically housed in temples and contained religious texts, but over time, libraries began to expand their collections to include works on various subjects [2].

Ishango bone
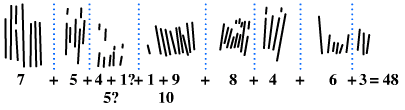
Using the bone for counting
Early humans also used numerical data for practical purposes. The Ishango bone, which is thought to be over 20,000 years old, is an example of early humans logging numerical data for later use. The bone, which was discovered in what is now modern-day Congo, contains tally marks that were likely used for counting [3].

Abacus
The abacus, a simple device used for arithmetic calculations, was believed to be invented by the Babylonians as early as 2400 BCE [4]. The abacus was widely used in Asia and Europe for centuries and is still used today in some parts of the world.

Antikythera Mechanism
The Antikythera Mechanism, discovered in an ancient Greek shipwreck in 1901, is the earliest known mechanical computer. It was likely built around 100 BCE and was used to predict astronomical positions and eclipses. The mechanism is made up of at least 30 bronze gears and is a testament to the sophisticated understanding of astronomy and mechanics in ancient Greece [5].
Data interpretation: the 1600s

Statistical data analysis on London parishes’ death records
The 1600s saw the emergence of statistics and the beginning of data interpretation. John Graunt, a London haberdasher, is widely regarded as the father of statistics for his pioneering work in the field. Graunt conducted the first recorded experiment in statistical data analysis by studying London parishes' death records in the mid-17th century [6].
Graunt's study was groundbreaking for its time. He was able to predict life expectancies, analyze death rates between genders, and eventually devise an early warning system for the bubonic plague, which was ravaging Europe at the time. Graunt's work laid the foundation for modern demographic research and helped establish the value of statistical analysis in decision-making processes [6].
The significance of Graunt's actions cannot be overstated. By recognizing the importance of data interpretation, Graunt paved the way for further development of the field. Today, statistics and data interpretation are used in a wide variety of fields, from business to healthcare, to help make better-informed decisions and predictions based on the available data.
Data processing: the 1800s
The 1800s saw the emergence of data processing, prompted by the US Census. With a population that was growing rapidly, the census process was becoming increasingly complex, and traditional methods of data collection and processing were no longer effective. The sheer volume of data collected would have made it difficult to process the information manually in a timely manner [7].

Hollerith tabulating machine
To address this issue, Herman Hollerith, an employee of the US Census Bureau, devised the Hollerith Tabulating Machine. This machine used punch cards to input data, and it could process data much more quickly than traditional methods. In the 1890 census, the Hollerith Tabulating Machine reduced processing time from 7.5 years to just 2.5 years [7].
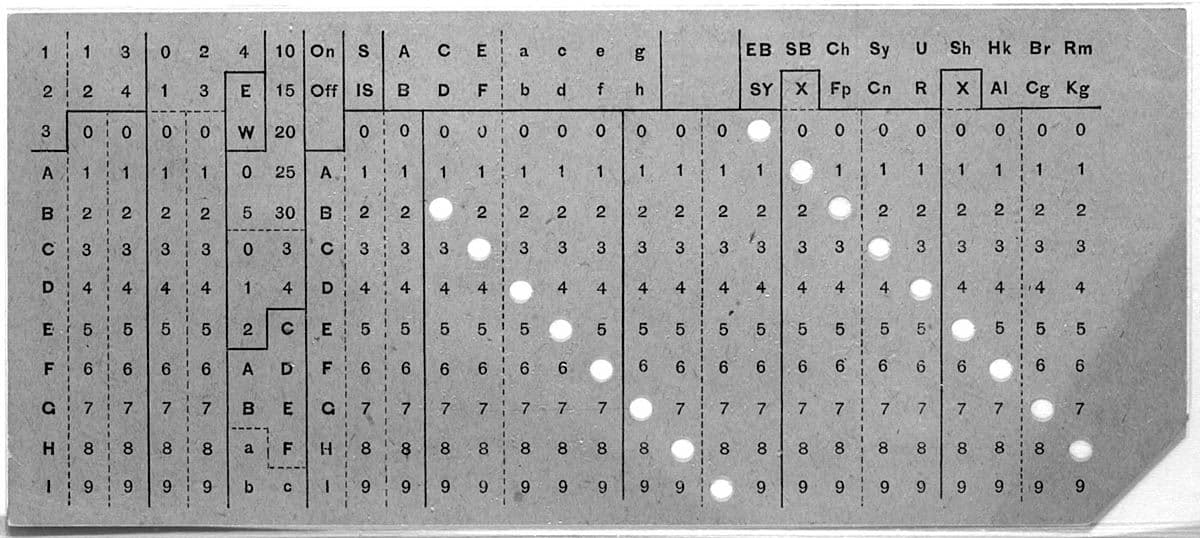
Punch card
The Hollerith Tabulating Machine was a significant development in modern automated computation, and it played a crucial role in the foundation of IBM. Hollerith's invention paved the way for the development of modern computing technologies, and his legacy can still be seen in the punch cards used in early computer systems and the concept of binary code [7].
Data storage: the 1900s
Following the question of data being processed, the 1900s saw an increased need for data storage. The need for data storage became more prominent as technology evolved, allowing for greater amounts of data to be collected and processed. The emergence of new storage technologies, such as magnetic tape and cloud storage, played a significant role in addressing this need [8].

Magnetic tape by Fritz Pfleumer
Fritz Pfleumer was a German engineer who invented the first magnetic tape in 1928. This technology allowed for data to be stored magnetically on tape, and it was used extensively for audio and video recordings. Magnetic tape became a popular storage medium for data storage and backup systems and was widely used by businesses and governments for many years [8].

SAGE system terminal that computers that showed data collected via network of computers
Dr Joseph Carl Robnett Licklider, a computer scientist, was one of the pioneers of cloud computing. In the 1960s, he conceptualized the idea of a network of computers that could communicate with each other and share resources. This concept eventually led to the development of cloud storage, which has become an essential technology for data storage and management [8].
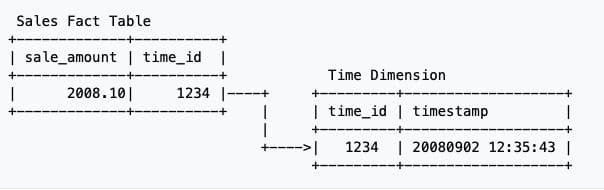
Relational database
Edgar F. Codd, a British computer scientist, developed the relational data management framework in the 1970s. This framework allowed for the storage and retrieval of data in a more efficient and structured manner, making it easier for organizations to manage large amounts of data. This framework is still widely used today in database management systems [8].
The term ‘Big Data’ came into existence in the late 1990s, with the surge in popularity of newly emerging software and systems for analyzing commercial and operational performance. Big Data refers to the massive amounts of data that organizations now collect and process, and the challenges associated with managing and analyzing this collected data. With the emergence of cloud computing and other data storage technologies, managing and analyzing Big Data has become more feasible [8].
Data and the internet: the 1990s
The emergence of the internet in the 1990s saw a significant shift in data collection, interpretation, and storage. The internet allowed for a more extensive range of data to be collected from various data sources, shared and analyzed by people across the world, regardless of their location.
Tim Berners-Lee played a significant role in the creation of the internet, which became an essential part of modern life, driving data-related industries forward. The ability to search for any topic on the internet became a turning point in data usage.
The launch of Google Search in 1997 was a major breakthrough, enabling mass amounts of data to reach anyone with a computer. Google Search algorithms and indexing mechanisms made it possible to sort through huge data sets, leading to a new era of data analysis.
Data storage evolved in the 1990s, with digital storage and retrieval of data becoming more commonplace and more cost-effective than paper storage. This led to the growth of more efficient data storage systems, including relational databases and data warehouses. As a result, businesses could store and manage their data more effectively, leading to more informed decision-making.
The development of the internet and the emergence of search engines marked a new era of data analysis, collection, and storage, leading to increased efficiency and accuracy in data processing.
Big Data evolution: early 2000s
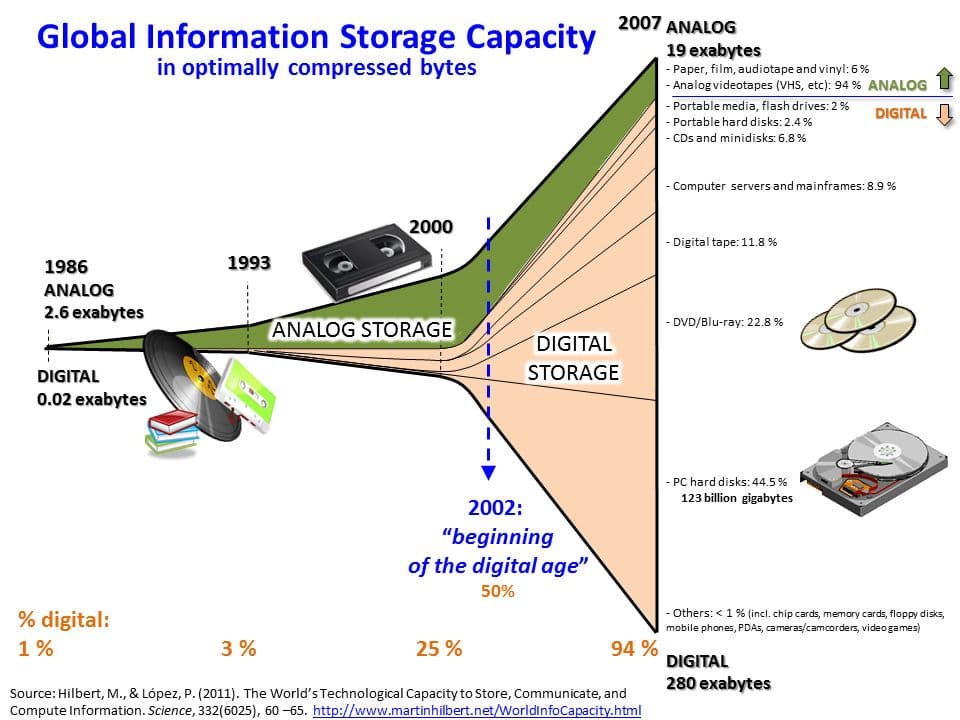
Big data history timeline
During the early 2000s, the phrase "Big Data" underwent a dramatic evolution and reconsideration. For the first time, researchers and thinkers attempted to quantify the amount of digital information in the world and its growth rate. The results were staggering, with estimates suggesting that the amount of data in the world was doubling every two years.
It was during this time that the concepts of cloud-based services and applications were introduced, and the importance of data insight was addressed. Big Data became the buzzword of the decade, with companies and governments investing heavily in technology to gain a competitive edge. The ability to collect, store, and analyze large amounts of data became a vital part of many businesses, enabling them to make more informed decisions and target customers more effectively.
Increased data volumes: 2005
The rise of Web 2.0 introduced user-generated content, leading to a shift in the way we look at data collection. In 2005, Tim O'Reilly introduced the concept of Web 2.0, emphasizing that most data on the internet would come from people using the service rather than the service themselves. This shift in data collection was further emphasized by the rise of social media platforms like Facebook, where users shared personal information and preferences on a global scale.
The integration of traditional HTML-style web pages with vast back-end databases built on SQL also became commonplace during this time. This allowed for dynamic and interactive websites, as well as more advanced data processing and analysis. The creation of Hadoop in 2006 further revolutionized data storage and processing, providing a scalable and cost-effective solution for Big Data analysis.
Big Data analytics: 2010s
In the 2010s, the term "Big Data" began to take on its current meaning. Companies were storing and processing more and more data on their servers, and at a conference in 2010, Google Chairman Eric Schmidt informed attendees that as much data is being created every two days as was created from the dawn of civilization until 2003. There are more than 2.5 quintillion bytes of data created each day [9].
This surge in data collection put pressure on companies to find data scientists and analysts who could interpret the data. Additionally, the rise of mobile phones further contributed to the growth of Big Data analytics, as more and more people began using their phones for daily tasks and generating massive amounts of data in the process.
The future of data
The future of data is exciting, and we can expect to see even more significant developments in the coming years. One of the most significant changes will be the growth of AI and machine learning, which will enable organizations to make more informed decisions based on data insights. With this development, there is a growing need for proper data ethics and use, ensuring that data is collected, processed, and analyzed ethically and responsibly. Cloud storage will continue to play a vital role in data storage, with an increasing number of companies turning to cloud-based solutions for their data management needs.
Recent significant developments in the field of data include the implementation of the General Data Protection Regulation (GDPR), which aims to protect the privacy of personal data of European Union citizens. Another area of development is training artificial intelligence systems to better understand and interpret data. This has helped shape vital technological advances such as facial recognition software and natural language processing, which can improve customer experience and provide valuable insights for businesses. Overall, we can expect data to continue to play a critical role in shaping the world we live in and driving innovation across industries.
Conclusion
Data collection is a long-standing practice that has been shaping human decisions and understanding for centuries. From the first experiments in statistics to the launch of the internet and the rise of Big Data, the history of data collection is full of significant events and figures. As we move into the future, new developments such as AI and machine learning, data ethics and use, and cloud storage are shaping how we approach data collection.
The history of data collection is still being written, and it is essential to stay informed and up to date with the latest trends and best practices. We encourage you to explore other sections in Rudderstack Data Collection Learning Center for a deeper understanding of how data collection can impact your business. Specifically, we recommend checking out What is data collection?, Data Collection Best Practices, and Methods of Data Collection.
References:
- "Clay Tablet," Wikipedia, accessed April 18, 2023, https://en.wikipedia.org/wiki/Clay_tablet.
- "The First Libraries," Ancient History Encyclopedia, accessed April 18, 2023, https://www.ancient.eu/article/1140/the-first-libraries/.
- "Ishango Bone," Wikipedia, accessed April 18, 2023, https://en.wikipedia.org/wiki/Ishango_bone.
- “Abacus”, New World Encyclopedia, accessed May 1, 2023 https://www.newworldencyclopedia.org/entry/Abacus
- "The Antikythera Mechanism," Wikipedia, accessed April 18, 2023, https://en.wikipedia.org/wiki/Antikythera_mechanism.
- "John Graunt," Encyclopædia Britannica, accessed April 18, 2023, https://www.britannica.com/biography/John-Graunt.
- "Herman Hollerith," Wikipedia, accessed April 18, 2023, https://en.wikipedia.org/wiki/Herman_Hollerith.
- "Data Storage," Wikipedia, accessed April 18, 2023, https://en.wikipedia.org/wiki/Data_storage.
- “How Much Data Do We Create Every Day?,” Forbes, accessed April 18, 2023, https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/.