RudderStack ETL Makes Cloud-to-Warehouse Pipelines Easy

When it comes to your customer data there, tend to be very common silos for many businesses. One is around the event data from different customer touchpoints, frequently residing in your customer data platform and streamed to different tools or in individual analytics tools (product, marketing, etc.).
Another common silo is your customer master data, frequently stored in Salesforce. Another could be around your paid advertising campaigns with data residing in Google Ads, Facebook Ads, and LinkedIn Ads. It only gets more complicated and siloed the more tools you use. Bringing all of these different types of customer data into one place is incredibly difficult, but if you can do it, your analysis can be deeper and drive more meaningful insights.
To help make this challenging technical problem simple, we are launching RudderStack ETL, including integrations with popular cloud tools like Salesforce, ZenDesk, and many more (even Google Sheets). ETL enables you to access and integrate data from your product, sales, marketing, support, and finance teams’ cloud tools (and databases/data lakes) to expand the types of analysis your teams can do and make the insights your teams derive more specific, accurate, and actionable.
In this post, we detail ETL. We explain how ETL works, some of the benefits of using it, and how to set it up in RudderStack.
How ETL Works
ETL allows you to collect raw data from different cloud tools, including Marketo, Facebook Ads, Google Ads, Google Analytics, Google Search Console, HubSpot, LinkedIn Ads, and many more. You can also pull data from databases and data lakes like Postgres, S3, and others.
The raw datasets from ETL can be routed to supported data warehouses (Snowflake, Google BigQuery, Amazon Redshift, ClickHouse, and PostgreSQL) for analysis.
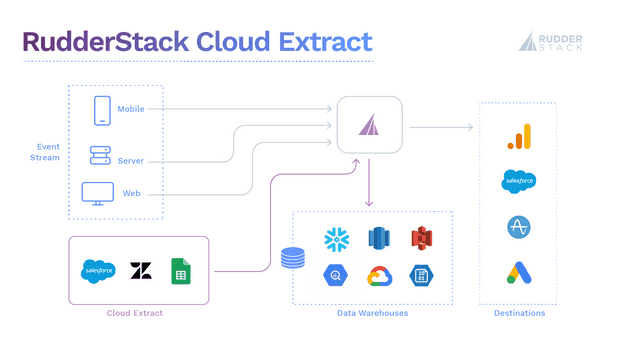
ETL architecture
Benefits of Using ETL
RudderStack Event Stream has always made it easy to aggregate customer event data from all of your digital touchpoints into your data warehouse. ETL extends this functionality, making it easy to send customer data from all your different third-party tools into your data warehouse. This enables you to easily combine data from different customer teams like product, sales, marketing, or support, so you can surface answers to more complicated, nuanced business questions. Then, with RudderStack Reverse ETL, you can easily feed these business insights into your pipelines, enriching customer events with data from in-warehouse analysis for activation in your downstream customer tools.
As an example, let's say you want to perform a deeper analysis on churn and understand the relationship between the number and type of customer support tickets and product usage. Normally, these are siloed data sets. With RudderStack, though, you can use Event Stream to collect product usage behavior and ETL to pull support tickets from Zendesk, then combine both data sets in your warehouse for analysis.
Let's say you identify some leading indicators of churn and use queries on your warehouse to build a "likely to churn" cohort. Using Reverse ETL, you can pull that cohort of users back through RudderStack as identify calls to update user profiles in all of your downstream tools, giving teams the ability to see and take action on users who have a higher likelihood to churn.
Setting up ETL in RudderStack
ETL integrations are easy to set up and maintain. Just use the ready-made connectors to connect to any data source, and your data will start flowing through RudderStack.
Let’s use a real-world example to walk through the setup. We will set up Salesforce as a ETL source and send the Lead object data to Snowflake.
- Log in to your RudderStack dashboard.
- Click on Sources on the left panel of your dashboard. Select Salesforce, and then click on Next.
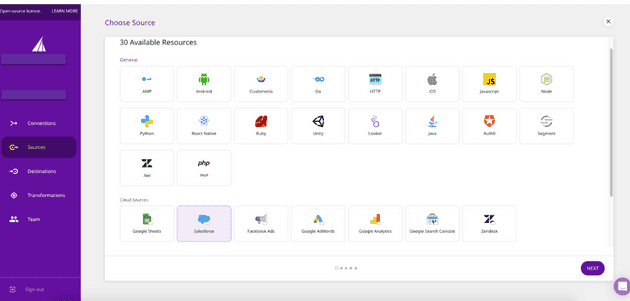
Picking Sources
- Name your source and click on Next.
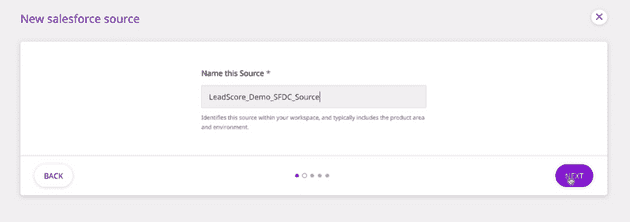
Naming the source
- Next, you will be required to authenticate your Salesforce account. To do so, click on Connect with Salesforce. After granting the necessary permissions, your account should be successfully connected and visible on the dashboard. Then, click on Next.
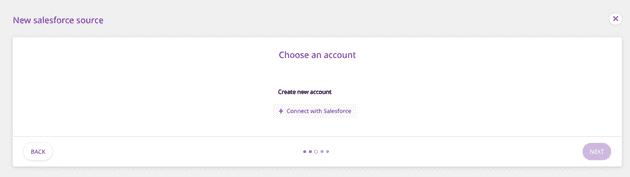
Authenticating the Salesforce Account
Note: If you have already logged into your Salesforce account previously, clicking on the Connect with Salesforce option will automatically connect that account to RudderStack. To connect to a different account, you will have to log out of your Salesforce account, then log in to the account you want to connect.
- In the next window, select the Run Frequency. This configuration controls how often RudderStack will pull data from your Salesforce integration. Then, click on Next.
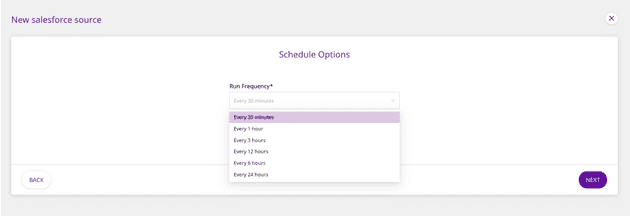
Deciding Run Frequency
- Next, choose the Salesforce data you want to pull through RudderStack and click on Next. You can choose to import selected Salesforce resources or choose all of them. In this example, we want to import the Lead object data, so we select Lead as shown.
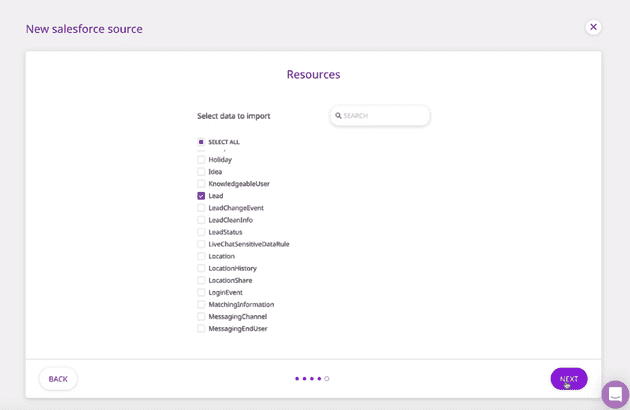
Choosing the Data
You have successfully configured Salesforce as a source in your RudderStack pipeline. RudderStack will start ingesting data at the specified frequency.
- Connect this source to your data warehouse by clicking on Connect Destinations or Add Destinations, as shown:
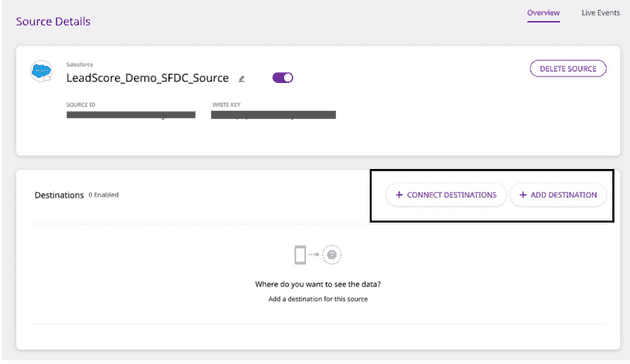
Connecting to the Warehouse
In this example, we will be importing the Lead data into Snowflake. Before setting up Snowflake as a destination, we need to create a database and a warehouse in Snowflake. We have also created an S3 bucket that acts as a staging area for the data flowing into Snowflake.
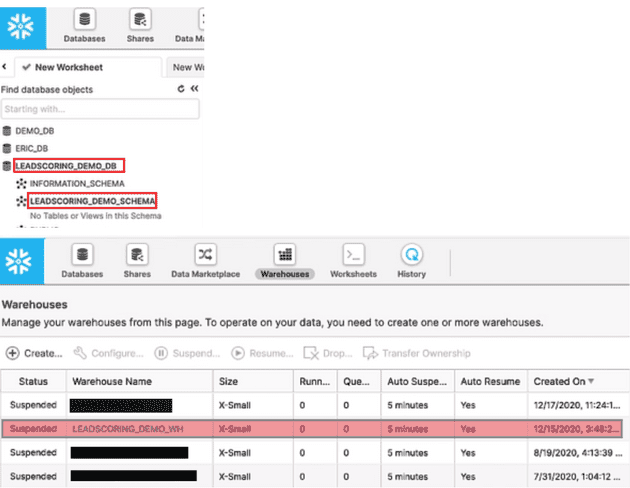
Importing Lead Data
- Next, name the destination and Connect it to your Cloud Source by adding all the required credentials in the Connection Credentials section.
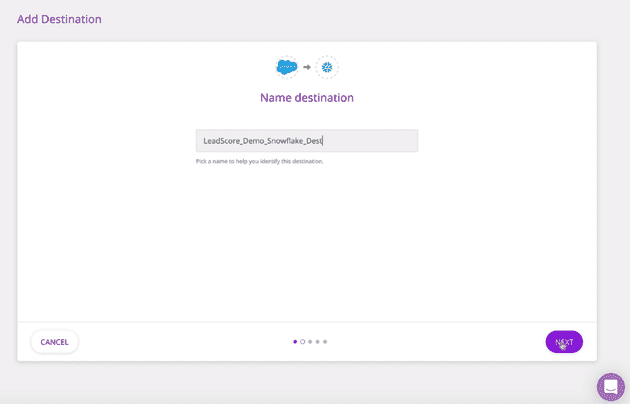
Naming Destinations
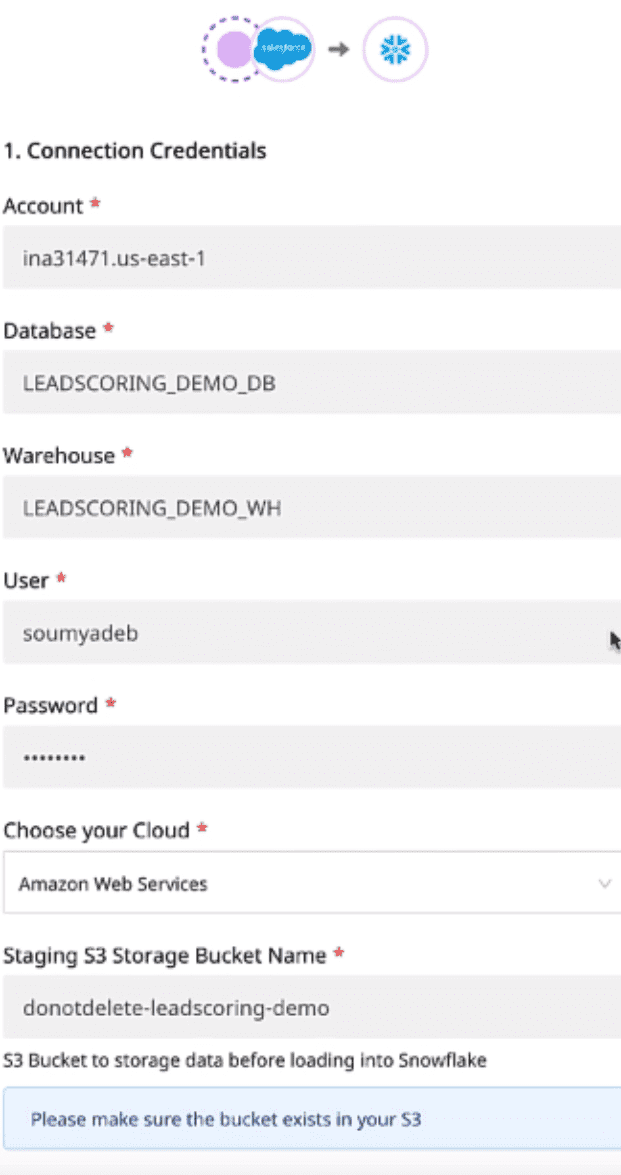
ETL
Next, you can choose to add a Transformation. You can choose no transformation, an existing transformation, or create a new one (in this example, we do not need any transformation).
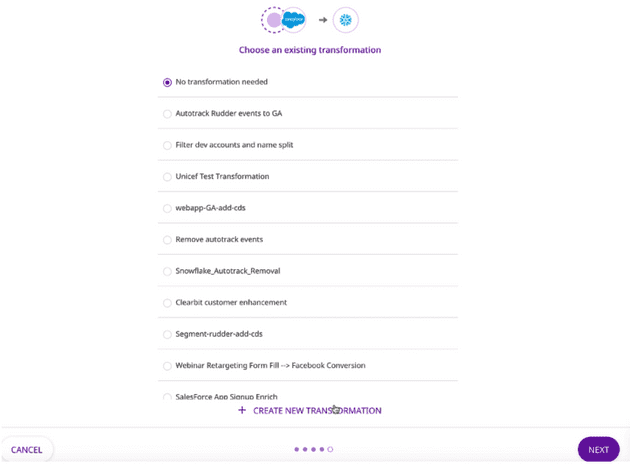
Adding a Transformation
That’s it! You have successfully added Snowflake as a destination for your Salesforce source. Your data will sync according to the schedule you defined. You can also trigger sync manually by clicking on Sync Now.
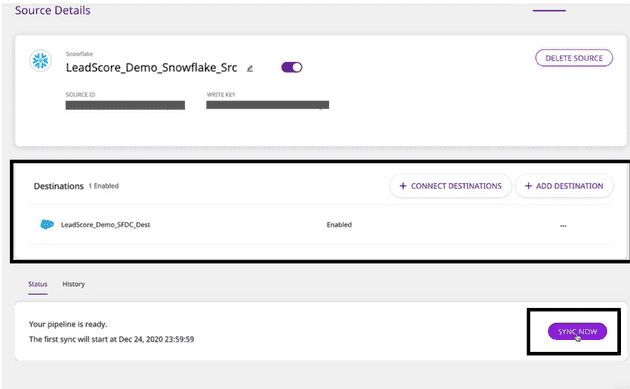
Syncing
Once the sync is completed, you can go to your Snowflake Dashboard to verify that the new Lead table is present and has been populated with data from the Salesforce:
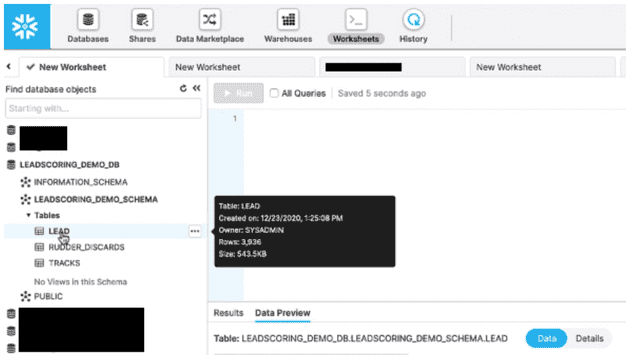
Snowflake Dashboard
To explore the different ETL Sources and to know more details, visit our documentation.
One of our clients, Proposify, has the following to say:
At Proposify, we get a lot of traffic from organic search sources. Being able to have insight into GSC data to monitor relevant search trends, keyword rankings, and landing page performance is crucial to inform everything from content, SEO, and inbound marketing. RudderStack’s ETL lets us seamlessly integrate this data into our Redshift warehouse and data modeling workflows for a complete view of our acquisition efforts. It’s a powerful turnkey solution! - Max Werner, Data Operations Manager at Proposify
Sign up for Free and Start Sending Data
Test out our event stream, ELT, and reverse-ETL pipelines. Use our HTTP source to send data in less than 5 minutes, or install one of our 12 SDKs in your website or app. Get started.
Published:
January 26, 2021

Understanding event data: The foundation of your customer journey
Understanding your customers isn't just about knowing who they are—it's about understanding what they do. This is where clean, accurate event data becomes a foundational part of your business strategy.


Event streaming: What it is, how it works, and why you should use it
Event streaming allows businesses to efficiently collect and process large amounts of data in real time. It is a technique that captures and processes data as it is generated, enabling businesses to analyze data in real time

How Zoopla transformed real estate experiences with data-driven personalization
Learn how Zoopla, a leader in the UK real estate space, transformed real estate experiences with data-driven personalization and RudderStack's customer data infrastructure.



